Dahil ang pampublikong paglulunsad nito 10 taon na ang nakalipas, ang Twitter ay ginagamit bilang isang social networking platform sa mga kaibigan, isang instant messaging service para sa mga gumagamit ng smartphone at isang promotional tool para sa mga korporasyon at mga pulitiko.
Ngunit ito rin ay isang napakahalaga na mapagkukunan ng data para sa mga mananaliksik at siyentipiko - tulad ng aking sarili - na gustong pag-aralan kung paano nararamdaman at gumana ang mga tao sa mga kumplikadong sistemang panlipunan.
Sa pag-aaral ng mga tweet, nakapagtala at nakakolekta kami ng data sa mga social interaction ng milyun-milyong tao "sa ligaw," sa labas ng mga kinokontrol na eksperimento sa laboratoryo.
Pinagana nito sa amin na bumuo ng mga tool para sa pagsubaybay sa sama ng damdamin ng mga malalaking populasyon, Hanapin ang pinakamaliligayang lugar sa Estados Unidos at marami pang iba.
Kaya paano, eksakto, ang Twitter ay naging tulad ng isang natatanging mapagkukunan para sa computational social siyentipiko? At ano ang nagpahintulot sa atin na matuklasan?

Ang pinakamalaking regalo ng Twitter sa mga mananaliksik
Noong Hulyo 15, 2006, Twittr (gaya ng pagkakilala noon) sa publiko Inilunsad bilang isang "serbisyong pang-mobile na tumutulong sa mga grupo ng mga kaibigan na mag-bounce ng random na mga saloobin sa paligid ng SMS." Ang kakayahang magpadala ng mga libreng teksto ng 140-character na grupo ay nagdulot ng maraming mga maagang tagagamit (kasama ang aking sarili) upang gamitin ang platform.
Sa oras, ang bilang ng mga gumagamit sumabog: mula 20 milyon sa 2009 hanggang 200 milyon sa 2012 at 310 milyon ngayon. Sa halip na direktang makipag-usap sa mga kaibigan, sasabihin lamang ng mga user ang kanilang mga tagasunod kung ano ang nadama nila, tumugon sa positibo o negatibong balita, o pumutok ng mga biro.
Para sa mga mananaliksik, ang pinakamalaking regalo ng Twitter ay ang pagkakaloob ng mga malalaking dami ng bukas na data. Ang Twitter ay isa sa mga unang pangunahing social network upang magbigay ng mga sample ng data sa pamamagitan ng isang bagay na tinatawag na Application Programming Interface (API), na nagbibigay-daan sa mga mananaliksik sa query Twitter para sa mga partikular na uri ng mga tweet (eg, mga tweet na naglalaman ng ilang mga salita), pati na rin ang impormasyon sa mga gumagamit .
Nagdulot ito ng pagsabog ng mga proyektong pananaliksik na gumagamit ng data na ito. Ngayon, isang paghahanap sa Google Scholar para sa "Twitter" ay gumagawa ng anim na milyong mga hit, kumpara sa limang milyon para sa "Facebook." Ang kaibahan ay lalo na kapansin-pansing ibinigay na ang Facebook ay halos limang beses bilang maraming mga gumagamit bilang Twitter (at dalawang taon na mas matanda).
Ang mapagkaloob na patakaran ng datos ng Twitter ay walang alinlangan na humantong sa ilang mahusay na libreng publisidad para sa kumpanya, tulad ng mga kagiliw-giliw na pang-agham na pag-aaral na kinuha sa pamamagitan ng mainstream media.
Pag-aaral ng kaligayahan at kalusugan
Sa tradisyonal na data ng sensus mabagal at mahal upang mangolekta, ang mga bukas na feed ng data tulad ng Twitter ay may potensyal na magbigay ng isang real-time na window upang makita ang mga pagbabago sa malaking populasyon.
Ang University of Vermont's Lab Computational Story ay itinatag sa 2006 at pag-aaral ng mga problema sa buong inilapat na matematika, sosyolohiya at pisika. Sapagkat 2008, ang Story Lab ay nakolekta ang bilyun-bilyong mga tweet sa pamamagitan ng feed na "Gardenhose" ng Twitter, isang API na nag-stream ng isang random na sample ng 10 porsiyento ng lahat ng mga pampublikong tweet sa real time.
Nagugol ako ng tatlong taon sa Computational Story Lab at masuwerteng bahagi ng maraming kawili-wiling mga pag-aaral gamit ang data na ito. Halimbawa, bumuo kami ng isang hedonometer na sumusukat sa kaligayahan ng Twittersphere sa real time. Sa pamamagitan ng pagtuon sa mga geolocated tweet na ipinadala mula sa mga smartphone, nagawa naming mapa ang pinakamaligayang lugar sa Estados Unidos. Marahil hindi nakakagulat, nakita namin Hawaii ay ang happiest estado at alak-lumalagong Napa ang happiest lungsod para sa 2013.
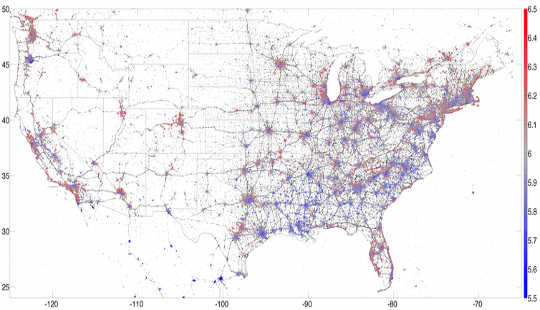 Isang mapa ng 13 milyong geolocated US tweet mula sa 2013, na kulay ng kaligayahan, na may red na nagpapahiwatig ng kaligayahan at asul na nagpapahiwatig ng kalungkutan. PLoS ONE, Ibinigay ang awtor.Ang mga pag-aaral na ito ay may mas malalim na mga application: Ang pagtutuos ng paggamit ng Twitter na salita sa mga demograpiko ay nakatulong sa amin na maunawaan ang napapailalim na socioeconomic pattern sa mga lungsod. Halimbawa, maaari naming iugnay ang paggamit ng salita sa mga kadahilanan sa kalusugan tulad ng labis na katabaan, kaya nagtayo kami ng isang lexicocalorimeter upang sukatin ang "caloric content" ng mga post sa social media. Ang mga tweet mula sa isang partikular na rehiyon na nagbanggit ng mga mataas na calorie na pagkain ay nadagdagan ang "caloric content" ng rehiyon na iyon, habang ang mga tweet na binanggit na ehersisyo ay nabawasan ang aming panukat. Nalaman namin na ang simpleng panukalang ito nauugnay sa iba pang mga sukatan sa kalusugan at kagalingan. Sa madaling salita, ang mga tweet ay nakapagbigay sa amin ng snapshot, sa isang partikular na sandali sa oras, ng pangkalahatang kalusugan ng isang lungsod o rehiyon.
Isang mapa ng 13 milyong geolocated US tweet mula sa 2013, na kulay ng kaligayahan, na may red na nagpapahiwatig ng kaligayahan at asul na nagpapahiwatig ng kalungkutan. PLoS ONE, Ibinigay ang awtor.Ang mga pag-aaral na ito ay may mas malalim na mga application: Ang pagtutuos ng paggamit ng Twitter na salita sa mga demograpiko ay nakatulong sa amin na maunawaan ang napapailalim na socioeconomic pattern sa mga lungsod. Halimbawa, maaari naming iugnay ang paggamit ng salita sa mga kadahilanan sa kalusugan tulad ng labis na katabaan, kaya nagtayo kami ng isang lexicocalorimeter upang sukatin ang "caloric content" ng mga post sa social media. Ang mga tweet mula sa isang partikular na rehiyon na nagbanggit ng mga mataas na calorie na pagkain ay nadagdagan ang "caloric content" ng rehiyon na iyon, habang ang mga tweet na binanggit na ehersisyo ay nabawasan ang aming panukat. Nalaman namin na ang simpleng panukalang ito nauugnay sa iba pang mga sukatan sa kalusugan at kagalingan. Sa madaling salita, ang mga tweet ay nakapagbigay sa amin ng snapshot, sa isang partikular na sandali sa oras, ng pangkalahatang kalusugan ng isang lungsod o rehiyon.
Gamit ang kayamanan ng data ng Twitter, nagawa rin namin tingnan ang pang-araw-araw na mga pattern ng kilusan ng mga tao sa walang katulad na detalye. Ang pag-unawa sa mga pattern ng mga tao na kadaliang mapakilos, ay magkakaroon ng kakayahang baguhin ang pag-model ng sakit, binubuksan ang bagong larangan ng digital epidemiology.
Para sa iba pang mga pag-aaral, tiningnan namin kung ang mga travelers ay nagpapahayag ng higit na kaligayahan sa Twitter kaysa sa mga naninirahan sa bahay (sagot: ginagawa nila) at kung ang mga maligayang tao ay malamang na magkakasama sa isang social network (muli, ginagawa nila). Sa katunayan, Ang positivity ay lilitaw upang maging luto sa wika mismo, sa diwa na mayroon tayong mas positibong salita kaysa negatibong mga salita. Hindi ito ang kaso sa Twitter kundi sa iba't ibang mga media (eg, mga libro, pelikula at mga pahayagan) at mga wika.
Ang mga pag-aaral na ito - at libu-libong iba pa tulad nila mula sa buong mundo - ay posible lamang salamat sa Twitter.
Ang susunod na mga taon ng 10
Kaya ano ang maaari naming asahan na matuto mula sa Twitter sa paglipas ng susunod na mga taon ng 10?
Ang ilan sa mga pinaka-kapana-panabik na trabaho ay kasalukuyang nagsasangkot ng pagkonekta ng data ng social media sa matematika na mga modelo upang mahulaan ang phenomena sa antas ng populasyon tulad ng paglaganap ng sakit. Ang mga mananaliksik ay may ilang mga tagumpay sa pagpapalaki ng mga modelo ng sakit na may Twitter na data upang mag-forecast ng influenza, kapansin-pansin ang FluOutlook platform na binuo ng Northeastern University at ng Institute for Scientific Interchange.
Still, maraming mga hamon ang nananatili. Ang data ng social media ay nagdurusa mula sa isang napakababang "ratio ng signal-to-ingay." Sa madaling salita, ang mga tweet na may kaugnayan sa isang partikular na pag-aaral ay madalas na nalunod ng hindi nauugnay na "ingay."
Samakatuwid, dapat tayong patuloy na maging malay sa kung ano ang tinatawag na "malaking data hubris"Kapag umuunlad ang mga bagong pamamaraan at hindi maging sobrang tiwala sa ating mga resulta. Ang konektado sa mga ito ay dapat na ang layunin upang makabuo ng mga hula na "interpretasyon ng glass" na kahon mula sa mga datos na ito (kumpara sa mga hula sa "black-box", kung saan ang algorithm ay nakatago o hindi malinaw).
Ang data ng social media ay kadalasang (medyo) pinupuna dahil sa pagiging isang maliit, sample na walang kinatawan ng mas malawak na populasyon. Ang isa sa mga pangunahing hamon para sa mga mananaliksik ay pag-uunawa kung paano isasaalang-alang ang naturang mga skewed na data sa mga istatistikang modelo. Habang mas maraming tao ang gumagamit ng social media bawat taon, dapat tayong patuloy na sikaping maunawaan ang mga biases sa data na ito. Halimbawa, ang data ay may posibilidad na mag-overrepresyon sa mga nakababatang indibidwal sa kapinsalaan ng mga mas lumang populasyon.
Pagkatapos lamang ng pagbuo ng mas mahusay na mga paraan ng pagwawasto ng bias ay mananaliksik ang mga mananaliksik na lubos na tiwala sa mga hula mula sa mga tweet.
Tungkol sa Ang May-akda
Lewis Mitchell, Lektor sa Applied Mathematics, University of Adelaide
Ang artikulong ito ay orihinal na na-publish sa Ang pag-uusap. Basahin ang ang orihinal na artikulo.
Mga Kaugnay Books
at InnerSelf Market at Amazon